I added a command to my development environment that generates a module dependency graph from the source code:
The code to generate the module dependency graph
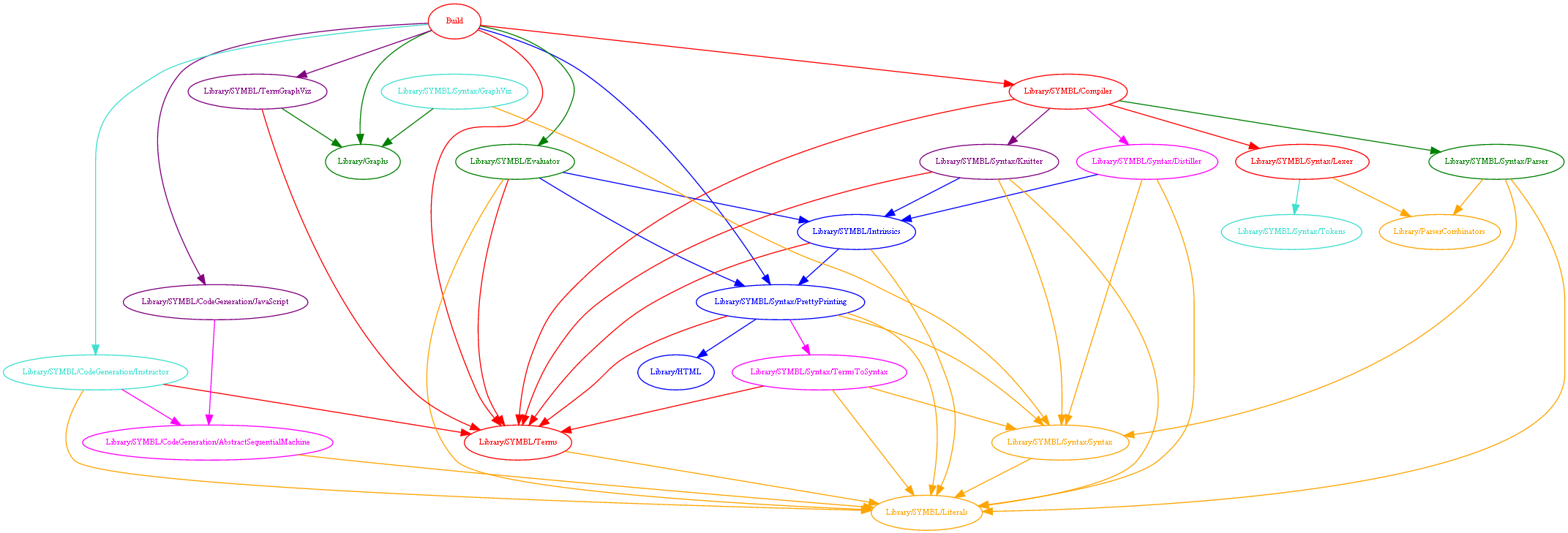
The module dependency graph
I added a command to my development environment that generates a module dependency graph from the source code:
The code to generate the module dependency graph
The module dependency graph
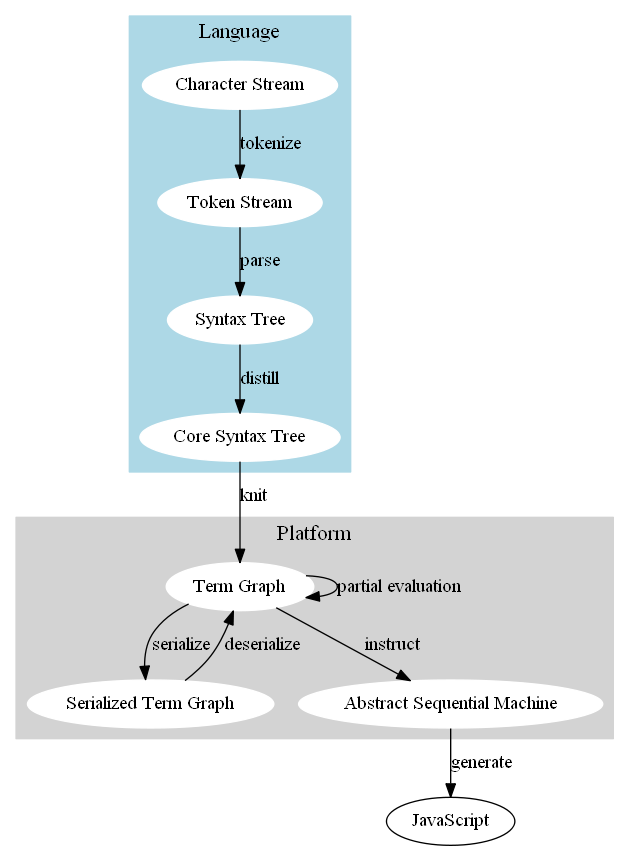
The compiler pipeline
Despite my recent fascination with space manufacturing, I’m still focusing on my programming language, which is tentatively called SYMBL. In November and December, I wrote a bootstrap compiler in CoffeeScript, and replaced the bootstrap compiler with a self-hosted compiler. Since then, I’ve been working toward adding static bounds checking.
A lot of my effort has gone into transforming the high-level language syntax into a minimal core language. After parsing, there is a distiller stage that reduces a syntax tree with 20 different types of non-literal nodes to a tree with 10 different types of non-literal nodes. The distiller turns most of the complex language features into the simplified core language:
The knitter follows the distiller, and turns the core syntax tree into a graph by replacing references to local definitions with direct references to the subtrees denoting the definition’s value, producing cycles for recursive definitions. The resulting graph has only 9 different types of non-literal nodes.
The result is a term graph which has very simple language-independent semantics. Most of the language’s semantics are defined by how the distiller and knitter translate its syntax into the semantics of the term graph, combined with the simple evaluation rules for the term graph.
The distiller and knitter were initially a single stage, but I found that splitting them into two stages produced simpler code: two 250 line modules can be much simpler than a 500 line module! And while this change didn’t reduce the amount of code in the stages themselves, the tests were simplified dramatically.
The term graph for the simplest module in the compiler
That distiller/knitter splitting was inspired by the success of splitting code generation into two stages. It previously generated JavaScript directly from the Term Graph. The translation into JavaScript is simple, but it needs to turn tail-recursive functions into imperative loops (JavaScript runtimes don’t have tail call optimization), and accommodate the distinction between expressions and statements that is typical in imperative languages like JavaScript (e.g. if is not an expression in JavaScript).
Instead of doing that in the same stage as the JavaScript generation, I defined an Abstract Sequential Machine that maps to a subset of JavaScript, and created a new Instructor stage that translates the Term Graph into the ASM. Because the ASM has the same structure as the JavaScript syntax tree, the generating JavaScript from the ASM is very simple.
The distiller/knitter split also matches this pattern of splitting a stage into a homomorphic (structure-preserving) part and a non-homomorphic part. The distiller is a homomorphic map from the syntax tree to the core syntax tree. I’m using homomorphic loosely here: the distiller is not truly homomorphic because repeat and array size shortcuts have a core syntax translation that is dependent on their context. But most of the syntax nodes are translated by the distiller independent of context! This context-independence leads to simple code, and much simpler tests.
There’s a point where simpler stages aren’t worth the additional complexity of more stages, but I think these two additional stages were a good trade-off.
I recently changed my comment syntax to allow multi-line comments through indentation, which you can see an example of in the below code. If a line comment is followed by indented lines, then the comment continues until the indentation level returns to the initial level.

This approach supports nesting, doesn’t require an explicit terminal symbol, and is also useful for string literal parsing.
There were two hard parts to implement it: