I added a command to my development environment that generates a module dependency graph from the source code:
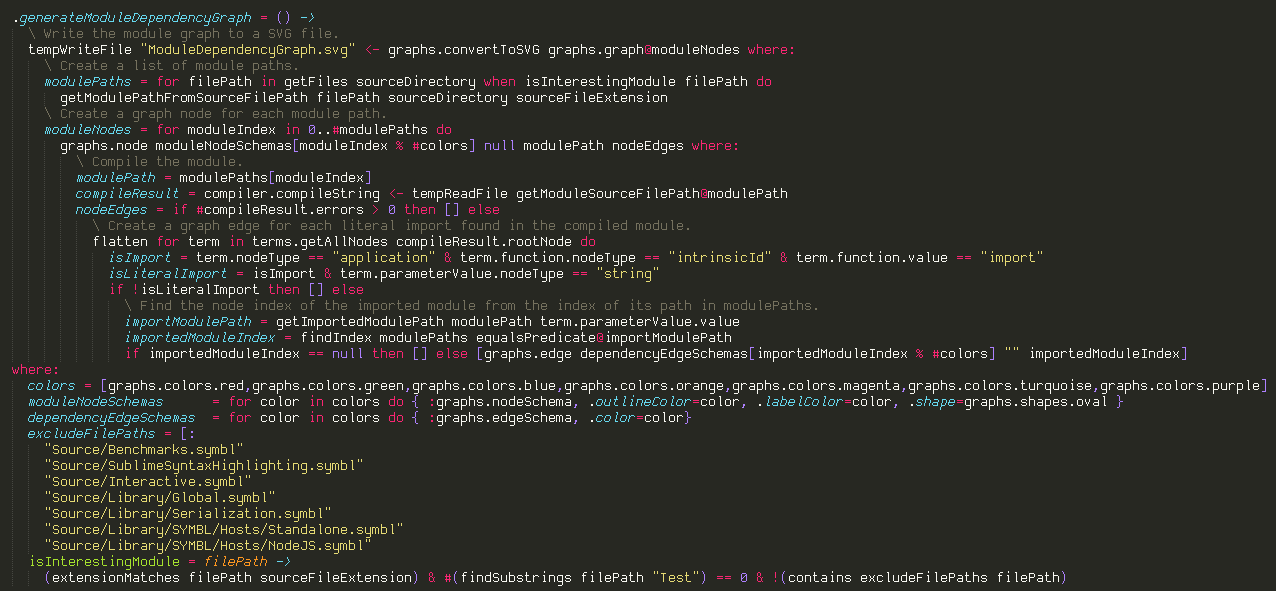
The code to generate the module dependency graph
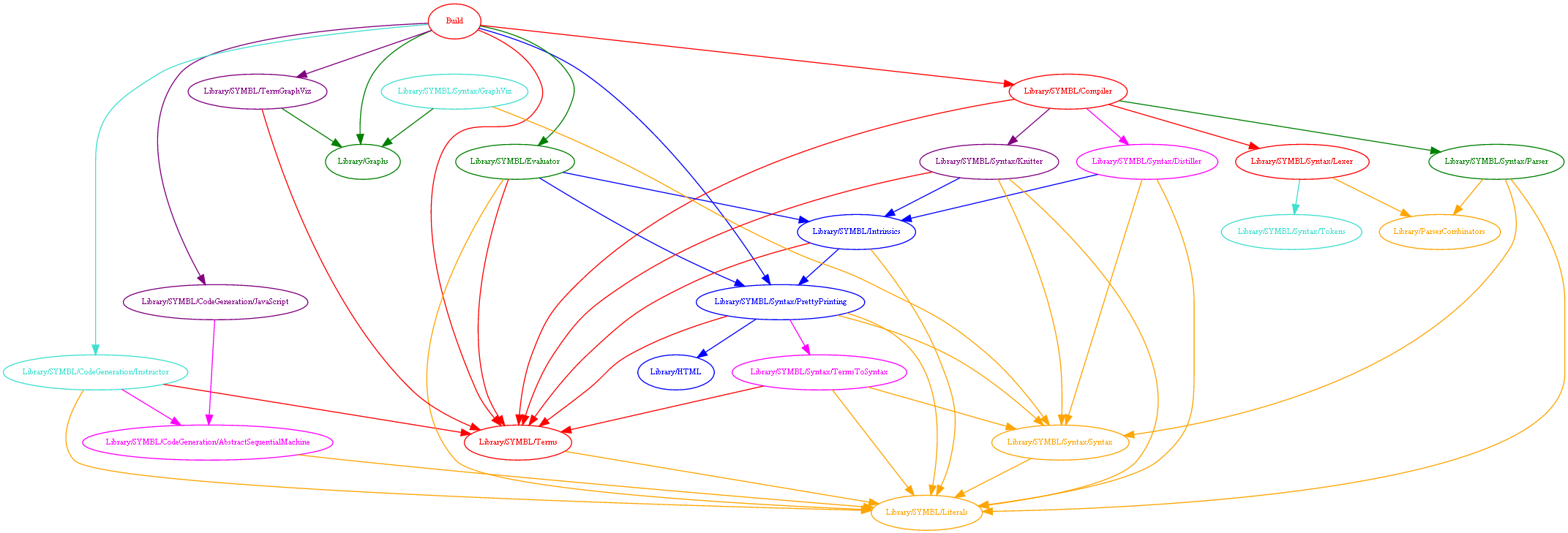
The module dependency graph
I added a command to my development environment that generates a module dependency graph from the source code:
The code to generate the module dependency graph
The module dependency graph
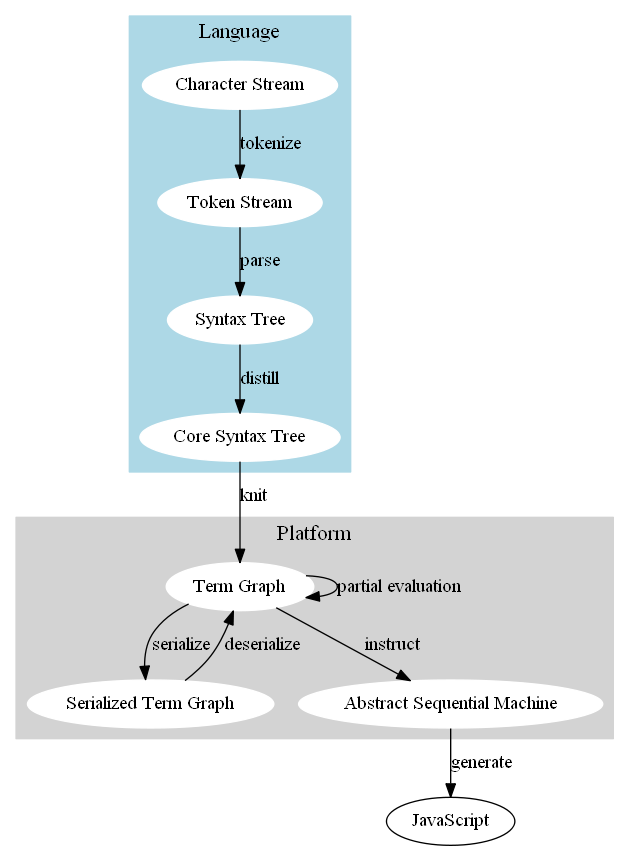
The compiler pipeline
Despite my recent fascination with space manufacturing, I’m still focusing on my programming language, which is tentatively called SYMBL. In November and December, I wrote a bootstrap compiler in CoffeeScript, and replaced the bootstrap compiler with a self-hosted compiler. Since then, I’ve been working toward adding static bounds checking.
A lot of my effort has gone into transforming the high-level language syntax into a minimal core language. After parsing, there is a distiller stage that reduces a syntax tree with 20 different types of non-literal nodes to a tree with 10 different types of non-literal nodes. The distiller turns most of the complex language features into the simplified core language:
The knitter follows the distiller, and turns the core syntax tree into a graph by replacing references to local definitions with direct references to the subtrees denoting the definition’s value, producing cycles for recursive definitions. The resulting graph has only 9 different types of non-literal nodes.
The result is a term graph which has very simple language-independent semantics. Most of the language’s semantics are defined by how the distiller and knitter translate its syntax into the semantics of the term graph, combined with the simple evaluation rules for the term graph.
The distiller and knitter were initially a single stage, but I found that splitting them into two stages produced simpler code: two 250 line modules can be much simpler than a 500 line module! And while this change didn’t reduce the amount of code in the stages themselves, the tests were simplified dramatically.
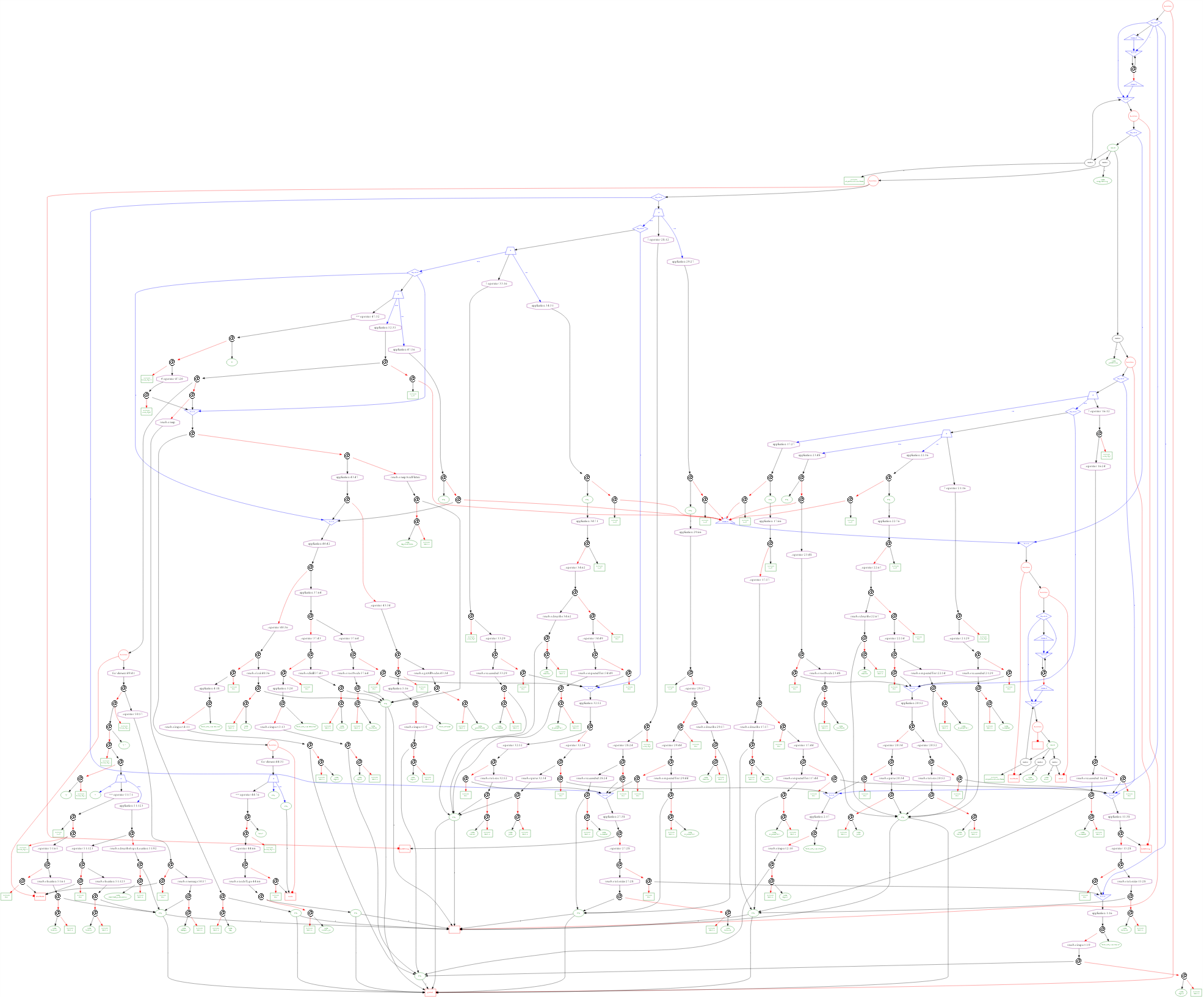
The term graph for the simplest module in the compiler
That distiller/knitter splitting was inspired by the success of splitting code generation into two stages. It previously generated JavaScript directly from the Term Graph. The translation into JavaScript is simple, but it needs to turn tail-recursive functions into imperative loops (JavaScript runtimes don’t have tail call optimization), and accommodate the distinction between expressions and statements that is typical in imperative languages like JavaScript (e.g. if is not an expression in JavaScript).
Instead of doing that in the same stage as the JavaScript generation, I defined an Abstract Sequential Machine that maps to a subset of JavaScript, and created a new Instructor stage that translates the Term Graph into the ASM. Because the ASM has the same structure as the JavaScript syntax tree, the generating JavaScript from the ASM is very simple.
The distiller/knitter split also matches this pattern of splitting a stage into a homomorphic (structure-preserving) part and a non-homomorphic part. The distiller is a homomorphic map from the syntax tree to the core syntax tree. I’m using homomorphic loosely here: the distiller is not truly homomorphic because repeat and array size shortcuts have a core syntax translation that is dependent on their context. But most of the syntax nodes are translated by the distiller independent of context! This context-independence leads to simple code, and much simpler tests.
There’s a point where simpler stages aren’t worth the additional complexity of more stages, but I think these two additional stages were a good trade-off.
I recently changed my comment syntax to allow multi-line comments through indentation, which you can see an example of in the below code. If a line comment is followed by indented lines, then the comment continues until the indentation level returns to the initial level.

This approach supports nesting, doesn’t require an explicit terminal symbol, and is also useful for string literal parsing.
There were two hard parts to implement it:
Something my language does differently from most object-oriented languages is that there’s no implicit this value for member functions. This may seem strange at first, but it solves a few problems.
A common problem with an implicit this value is that the function must be called explicitly as a member function to receive the this value. For example, in JavaScript, calling object.function() passes object into function as this. One case where this goes wrong is if you want to use that function as a delegate: control.onClick = object.function. Now, when control.onClick() is called, it will pass control to function as this instead of object. This is sometimes useful, but it’s unintuitive behavior for a function originally declared as part of object. JavaScript provides a way to override the this pointer passed to the function, but the fact that this may not be the object the function was declared in is a caveat most JavaScript programmers will have to deal with.
The next level of this problem is that when you have nested object declarations, this only allows you to access the innermost object’s members. That sounds a little contrived, but it’s a real problem. For example, if you have an object for your module’s public members, and within it you have another object literal, that nested object’s member definitions cannot access the module’s public members.
This is actually a little better in JavaScript than in languages like C++, since each object has its own map from member names to values. Since a function value in JavaScript includes an implicit lexical closure, the member function for an object can have implicit information about its lexical environment. That normally doesn’t include this, but it allows CoffeeScript to generate JavaScript that binds a function value to a specific value of this, so it will be the same regardless of how the function is called. However, that solution still requires programmers to understand how JavaScript defines this, so they can decide which functions need the special this-binding function syntax, and it doesn’t solve the problems with nesting objects. For more info, see CoffeeScript’s function binding.
The way I solved this in my language is to replace the caller-provided this with capturing the object’s members as part of a lexical closure. Object members may be accessed within the scope of the object definition, and it will resolve to the inner-most object that defines the name. Internally, there isn’t a single this, and member names need to be resolved against a stack of objects that were in the lexical scope.
To make things a little bit clearer for everybody (humans and machines), member names must start with a . symbol, both when declared and when accessed. Objects may also include definitions that don’t have a . prefix, but they are the equivalent of private members: they cannot be accessed outside the object definition. When an object is used as a prototype, its public and private members are copied into the derived object, and are bound to the new object where they previously accessed the prototype’s public members.

Member name resolution in my language
There are still some remaining problems:
For the last month, I’ve been working on a programming language. It’s the first language I’ve made, so I’ve been learning and having fun. It still has a long way to go, but a week ago it became self-hosted. I deprecated the bootstrap compiler (written in CoffeeScript), and haven’t looked back!
The language is similar to CoffeeScript in spirit, but is growing in a different direction. It’s dynamically typed, translated to JavaScript, has string subexpressions (what CoffeeScript calls string interpolation), and has significant white-space.
However, it also has no mutable variables, doesn’t use parentheses or commas for function calls, and has a different object model. I’m planning to incrementally add static typing: first by adding type constraints to function parameters that are verified at run-time, and then by verifying the constraints at compile time. The language already generates code with extra run-time checks to catch errors earlier than they would occur in CoffeeScript/JavaScript.

Snippet of my language
The where term seen in this snippet is a simple feature, but provides a useful tool for describing your program in a top-down way. The for is similar to CoffeeScript; in this case it means return an array where each element is the result of applying literalTokenParser … to the symbol strings in the provided array. [: is a way to declare a literal array with an indented list of elements separated by newlines, with a decrease in indentation terminating the array rather than an explicit ]. There are several terms like that in the language, inspired by my experience with CoffeeScript. In CoffeeScript, you often end up with redundant closing brackets and braces where the indentation provides the same information.
But I’ll talk more about my language later, this post is mostly about parser combinator error handling!
The code snippet shows a very simple example of parser combinators: litSeq is a primitive parser that matches a string in the input, literalTokenParser turns a successful match of that parser into a literal token value, and alt matches any individual symbol parsers. describeParser just provides a friendly description of the combined parser for debugging and error messages.
litSeq, literalTokenParser, alt and describeParser are all higher-order functions: they return a function that is parameterized by the input stream to be parsed. The type of symbolsParser is a function that maps an input stream cursor to either some output value and a new stream cursor, or failure.
Implicit in the alt combinator is the ability to backtrack. One of the alternatives may partially match the input stream, but ultimately fail and fall back to trying other alternatives at the earlier location in the stream. This is a powerful property that allows general composition of parsers: alt doesn’t need to know which characters each alternative will match to work. It’s also a dangerous feature, as a grammar with too much backtracking can be slow to parse and hard to read.
But the compositional nature of alt makes it possible to declare parsers like symbolsParser that may later be combined into more complicated parsers without any knowledge of what characters it matches. This kind of modularity allows reducing a program to its pieces, and reading and reasoning about each piece individually. Without it, complicated software projects eventually collapse under the weight of the knowledge needed to understand any given part of the project.
This modularity is why I prefer parser combinators to the usual shift-reduce parsers and the accompanying domain-specific languages that are often needed to practically develop them.
Some aspects of traditional parsing are still relevant, though. To accommodate parsing without backtracking, shift-reduce parsers are usually split into two passes: the first pass, lexing, turns a sequence of characters into a sequence of tokens. The second pass turns the sequence of tokens into a syntax tree. The first pass can turn character sequences like “for” into a single token, so that the second parsing pass only needs to look at the next token to tell that it’s a for statement, instead of a variable name starting with “f” or any number of other alternatives.
With backtracking parser combinators, you can express grammars that need to read many characters to determine which alternative is being parsed, but it is still often simpler to do it in two passes. The lexer can eliminate comments and insignificant white-space from the resulting token stream, which reduces complexity in the parser more than it adds complexity in the lexer.
In my language, the significant white-space is also translated in a separate pass from parsing and lexing. Tab characters at the start of lines are converted into indent and outdent tokens, which allows the parsing to be context-free. When the parser is trying to match a reduction in indent level, it doesn’t need to keep track of the current indent level; it just looks for an outdent token.
The lexer is also complicated by support for string subexpressions: the subexpressions within a string are recursively lexed, and so the raw output of the lexer is a tree of tokens that is flattened before being passed to the parser.
This is why string subexpressions complicate lexing
In my first implementation of the language in CoffeeScript, I used a special parser combinator to turn parse failures into fatal errors. For example, you know that in your grammar that the for keyword must be followed by an identifier, so you can say that the identifier parser is required. If that sequence parser matches the for keyword, but the following required identifier parser fails, then it is a fatal error.
However, that approach breaks the composability of the parsers. To add that required qualifier to the identifier parser, you need to know that no other parser in the whole grammar can match the for keyword followed by a non-identifier. It is true in this case, but it subtly effects the meaning of any parser using the for subparser. If you wanted to add an alternative use of for to the grammar, you would have to change that required identifier parser.
When I rewrote the parser in my language, I implemented the parser combinators differently. Whenever a parser fails, it also returns information about what it expected to parse. The parser combinators propagate that failure information outward, but may be absorbed if an alternative parser succeeds. Only when the failure is returned from the outermost parser does it become an error. At that point, the failure has information about all the alternatives at the point of failure, and can be turned into a useful error message. The rules for propagating the failures are fairly obvious, but took some trial and error for me to discover them:
Once the failure becomes fatal, it will have information about all the possible expectations at the furthest unmatched point in the input, organized in a tree with the nodes providing context for the failed expectations. To describe this to the user, I use the description for each leaf, and the innermost node that contains all the leaves as context.
Automatically generated parse error for a statement in my language’s REPL
Since leaving Epic, I’ve had the opportunity to revisit a lot of the tools I use for programming. Here are some thoughts on the tools I’ve been using:
This is a radical change after working in C++/HLSL for so long. CoffeeScript is just a syntax layer on top of JavaScript, so the trade offs are similar: dynamically typed, and runs everywhere. However, it fixes a few problems of JavaScript: it disallows global variables, and it creates lexical scopes for variables inside if/for blocks.
It’s also a significant white-space language, which is blasphemy to a C++ programmer, but using it has solidified my opinion that it’s The Right Way. {} languages (C++, Java, etc) all require indentation conventions to make the code readable; because when a human looks at the code we see the indentation rather than the curly braces. Significant indentation matches up our visual intuition with the compiler’s semantics.
It also doesn’t distinguish statements from expressions, and generally encourages writing functional-style code. Code blocks may contain multiple expressions, but “return” the value of their last expression. Loops are like comprehensions in Haskell; they yield an array with a value for each iteration of the loop, and if/else yields the value of the branch taken.
Lastly, it has “string interpolation”, which is a funny way to say that you can embed expressions in strings:
"Here is the value of i: #{i}"
This turns into string concatenation under the covers, but it’s nicer than writing it explicitly, and is less error-prone than C printf or .Net string.Format.
This comes along with CoffeeScript (as the compiler host), but is an interesting project on its own: it’s a framework for people using JavaScript to write servers (or other non-browser based JavaScript application).
My game developer instincts say that using JavaScript, a hopelessly single-threaded language, to write server code won’t scale. But using threads for concurrency when developing scalable servers is a distraction; you have to scale to multiple processes, so that may as well be your primary approach to concurrency. The efficiency of any single process is a constant factor on operating costs, but many web applications will simply not work at scale without multi-process concurrency.
NodeJS also benefits from the lack of a standard I/O API for JavaScript by starting with a clean slate. The default paradigm is asynchronous I/O, which is crucial in a single-threaded server. JavaScript makes this asynchronous code easier to write with lexical closures, and CoffeeScript makes it easier with significant indentation and concise lambda functions. Here is the Hello World example from the NodeJS website written in CoffeeScript:

Node.JS also takes advantage of dynamic typing (and again, a clean slate) to form modules from JavaScript objects. In the above code, http is a NodeJS standard module, but you use the same module system to split your program up into multiple source files. In each source file, there is an implicit exports object; you can add members to it, and any other file that “requires” your file will get the exports object as the result.
After a long time assuming that none of the standalone text editors were worth abandoning Visual Studio for, I was forced to try Sublime Text while in search of CoffeeScript syntax highlighting. I haven’t looked back. It is responsive, pretty, and has a unique and useful multiple selection feature.
You can use it for free with occasional registration nags, but if you do, I’m sure that you will agree that it’s worth the price ($60).
This is a font is designed for programmers; all the symbols look nice, and i/I/l/1 are all distinct. The CoffeeScript/NodeJS example above uses it. I’ve been using this font for years, though I had to abandon it when Visual Studio 2010+ removed support for bitmap fonts. Now that I’m using Sublime Text, I can use it again.
The argument for a bitmap font is that our displays aren’t high enough resolution to render small vector fonts well. TTF rendering ends up with lots of special rules for snapping curves to pixels, and Windows uses ClearType to get just a little extra horizontal resolution. It’s simpler to just use a bitmap font that is mapped 1:1 pixels. This will all change once we have “retina” resolution desktop monitors; 200 DPI should be enough to render really nice vector fonts on a desktop monitor.
As a sidenote, Apple has always tried to render fonts faithfully to how they would look printed, without snapping the curves to make them sharper on relatively low DPI displays. The text in MacOS/iOS looks a little softer than Windows as a result. That weakness is solved by high DPI displays; I’m waiting for my 30″ retina LCD, Apple!
My plan was initially to use Perforce; I even went to the trouble of setting up a Perforce server with automated online backup on a Linux VM (and believe me, that is trouble for somebody who isn’t a Linux guy). But after going to that trouble, I had to go visit my family in Iowa on short notice, and wasn’t able to get a VPN server running before I left. While I was in Iowa, I wrote enough code that I decided that I needed revision control enough to use Git temporarily until I got home. And it’s not great, but it works.
One interesting aspect of it is that editing is not an explicit source control action. Instead, Git tries to detect changes you’ve made to your local files. Committing those changes is still explicit, but in the UI I’m using (GitHub) files you’ve modified just automatically show up in the list of files you may commit. A nice side-effect of this is that it can detect renames (and theoretically copies, although I haven’t gotten that working). So you can move files around in Windows Explorer, and Git will notice that the contents are the same (or even mostly the same), and track it as a rename instead of a delete/add.
I’ve been using the GitHub frontend for Windows, but it’s very basic. The UI is pretty, but doesn’t expose a lot of the functionality of Git. It’s still a better workflow than using the command-line for seeing what your local changes are and committing, but there’s no way to see the revision history for a file or other things that I did all the time in the Perforce UI (as ugly as it was).
But it works well enough for my purposes that I have stuck with it after my trip to Iowa. I have my repository in my Dropbox, and so it’s transparently backed up and synced between my laptop and PCs. At some point, I will have to add a server component, but as long as I’m working by myself, Git works just fine without a server.
I’ve updated Personal Genome Explorer to version 1.2 (install, source). If you installed the previous version, it should offer to automatically update itself to the new version the next time you run it.
Changes:
|
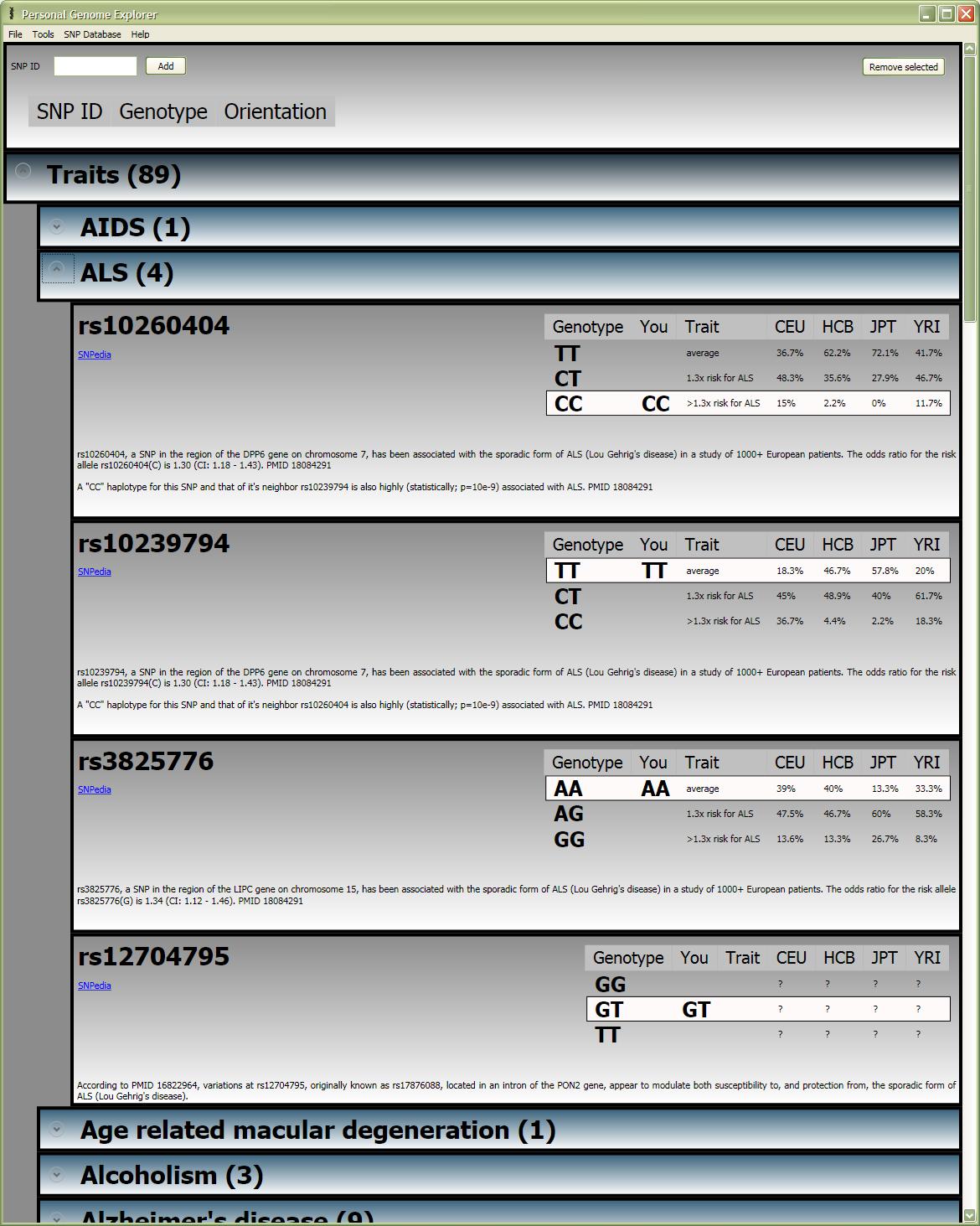 Screenshot Screenshot |
It looks like 23andme and deCODEme have both started to allow users to download their raw genome data.
I’ll try to update Personal Genome Explorer to import the data ASAP, but I may not have the time to put together a new release until next weekend.
I’ve posted version 1.1 of Personal Genome Explorer; both source and binaries are available.
Welcome to my blog. You can read a little bit about me here.
I’ve just posted the first source release of Personal Genome Explorer. It features data import from 23andme, an encrypted file format, and a basic analysis UI framework. However, there aren’t any real analyses yet; I’m just releasing this for those who would like to download their personal genome data from 23andme, and get started hacking. Enjoy!