For the last month, I’ve been working on a programming language. It’s the first language I’ve made, so I’ve been learning and having fun. It still has a long way to go, but a week ago it became self-hosted. I deprecated the bootstrap compiler (written in CoffeeScript), and haven’t looked back!
The language is similar to CoffeeScript in spirit, but is growing in a different direction. It’s dynamically typed, translated to JavaScript, has string subexpressions (what CoffeeScript calls string interpolation), and has significant white-space.
However, it also has no mutable variables, doesn’t use parentheses or commas for function calls, and has a different object model. I’m planning to incrementally add static typing: first by adding type constraints to function parameters that are verified at run-time, and then by verifying the constraints at compile time. The language already generates code with extra run-time checks to catch errors earlier than they would occur in CoffeeScript/JavaScript.

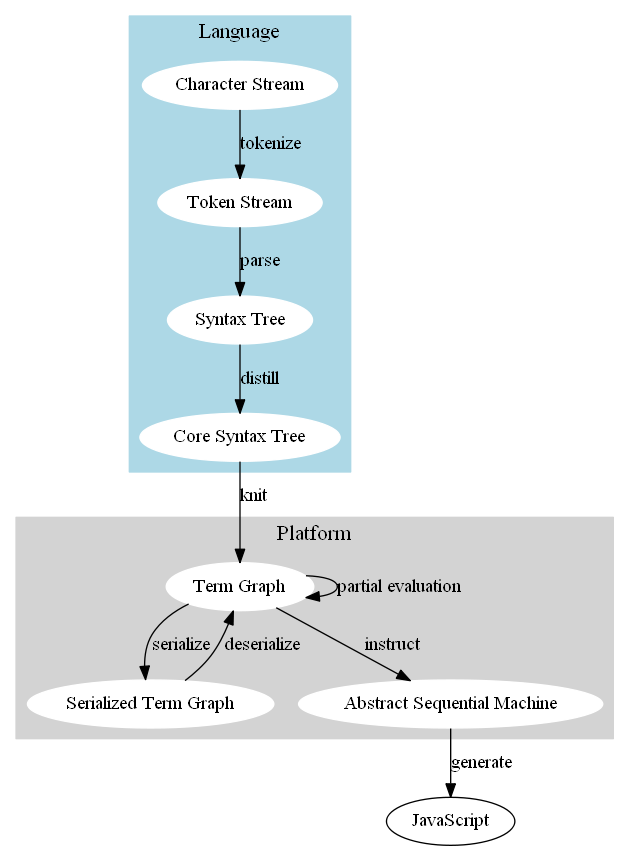
Snippet of my language
The where term seen in this snippet is a simple feature, but provides a useful tool for describing your program in a top-down way. The for is similar to CoffeeScript; in this case it means return an array where each element is the result of applying literalTokenParser … to the symbol strings in the provided array. [: is a way to declare a literal array with an indented list of elements separated by newlines, with a decrease in indentation terminating the array rather than an explicit ]. There are several terms like that in the language, inspired by my experience with CoffeeScript. In CoffeeScript, you often end up with redundant closing brackets and braces where the indentation provides the same information.
But I’ll talk more about my language later, this post is mostly about parser combinator error handling!
Parser combinators
The code snippet shows a very simple example of parser combinators: litSeq is a primitive parser that matches a string in the input, literalTokenParser turns a successful match of that parser into a literal token value, and alt matches any individual symbol parsers. describeParser just provides a friendly description of the combined parser for debugging and error messages.
litSeq, literalTokenParser, alt and describeParser are all higher-order functions: they return a function that is parameterized by the input stream to be parsed. The type of symbolsParser is a function that maps an input stream cursor to either some output value and a new stream cursor, or failure.
Implicit in the alt combinator is the ability to backtrack. One of the alternatives may partially match the input stream, but ultimately fail and fall back to trying other alternatives at the earlier location in the stream. This is a powerful property that allows general composition of parsers: alt doesn’t need to know which characters each alternative will match to work. It’s also a dangerous feature, as a grammar with too much backtracking can be slow to parse and hard to read.
But the compositional nature of alt makes it possible to declare parsers like symbolsParser that may later be combined into more complicated parsers without any knowledge of what characters it matches. This kind of modularity allows reducing a program to its pieces, and reading and reasoning about each piece individually. Without it, complicated software projects eventually collapse under the weight of the knowledge needed to understand any given part of the project.
This modularity is why I prefer parser combinators to the usual shift-reduce parsers and the accompanying domain-specific languages that are often needed to practically develop them.
Some aspects of traditional parsing are still relevant, though. To accommodate parsing without backtracking, shift-reduce parsers are usually split into two passes: the first pass, lexing, turns a sequence of characters into a sequence of tokens. The second pass turns the sequence of tokens into a syntax tree. The first pass can turn character sequences like “for” into a single token, so that the second parsing pass only needs to look at the next token to tell that it’s a for statement, instead of a variable name starting with “f” or any number of other alternatives.
With backtracking parser combinators, you can express grammars that need to read many characters to determine which alternative is being parsed, but it is still often simpler to do it in two passes. The lexer can eliminate comments and insignificant white-space from the resulting token stream, which reduces complexity in the parser more than it adds complexity in the lexer.
In my language, the significant white-space is also translated in a separate pass from parsing and lexing. Tab characters at the start of lines are converted into indent and outdent tokens, which allows the parsing to be context-free. When the parser is trying to match a reduction in indent level, it doesn’t need to keep track of the current indent level; it just looks for an outdent token.
The lexer is also complicated by support for string subexpressions: the subexpressions within a string are recursively lexed, and so the raw output of the lexer is a tree of tokens that is flattened before being passed to the parser.

This is why string subexpressions complicate lexing
Error reporting
In my first implementation of the language in CoffeeScript, I used a special parser combinator to turn parse failures into fatal errors. For example, you know that in your grammar that the for keyword must be followed by an identifier, so you can say that the identifier parser is required. If that sequence parser matches the for keyword, but the following required identifier parser fails, then it is a fatal error.
However, that approach breaks the composability of the parsers. To add that required qualifier to the identifier parser, you need to know that no other parser in the whole grammar can match the for keyword followed by a non-identifier. It is true in this case, but it subtly effects the meaning of any parser using the for subparser. If you wanted to add an alternative use of for to the grammar, you would have to change that required identifier parser.
When I rewrote the parser in my language, I implemented the parser combinators differently. Whenever a parser fails, it also returns information about what it expected to parse. The parser combinators propagate that failure information outward, but may be absorbed if an alternative parser succeeds. Only when the failure is returned from the outermost parser does it become an error. At that point, the failure has information about all the alternatives at the point of failure, and can be turned into a useful error message. The rules for propagating the failures are fairly obvious, but took some trial and error for me to discover them:
- I discard all alternative failures that matches less input than another failure, under the assumption that the parser that matched the most input is what the user intended.
- The describeParser combinator is used to provide a friendly description of what an inner parser will match. When the inner parser fails, if it didn’t match any input, it overrides the inner parser’s description of its expectations. However, if the inner parser fails after matching some input, then it forms an expectation tree where the description is used as context for the inner parser’s failed expectations.
- Because some parsers may have alternatives that succeed with a partial match of the input, they need to also return information about failed alternatives that consumed more input than the successful match. For example, parsing an addition expression from “a+” should successfully match “a”, and return that along with a failed alternative that matched “a+” but then failed to match a term.
- When a sequence parser fails, it needs to look at the failed alternatives for successfully matched subparsers at the beginning of the sequence, in addition to the subparser failure that caused the sequence to fail. For example, if the expression parser in the previous point was wrapped in a sequence that expected an expression followed by the end of the input, and was applied to the same input string “a+”, then it would match “a” before failing to match “+” with the end of the input. In that case, the failed alternative from the expression parser made it farther than the failed end of input parser, and so that is the failed expectation to return from the sequence.
Once the failure becomes fatal, it will have information about all the possible expectations at the furthest unmatched point in the input, organized in a tree with the nodes providing context for the failed expectations. To describe this to the user, I use the description for each leaf, and the innermost node that contains all the leaves as context.

Automatically generated parse error for a statement in my language’s REPL